Introduction
Aspect-based Sentiment Analysis (ABSA) has been a hot topic in the field of natural language processing in recent years.
Existing ABSA research primarily deals with single text pieces, such as reviews and comments.
There lies immense potential for the application of ABSA within dialogue-based contexts, a potential that remains largely untapped in the real world.
For instance, the successful deployment of ABSA on social media platforms could yield profound insights into the sentiments and perspectives of people as they engage in discussions on diverse topics, be it products, services, or political matters.
Regrettably, ABSA analysis in dialogue contexts has been insufficiently explored.

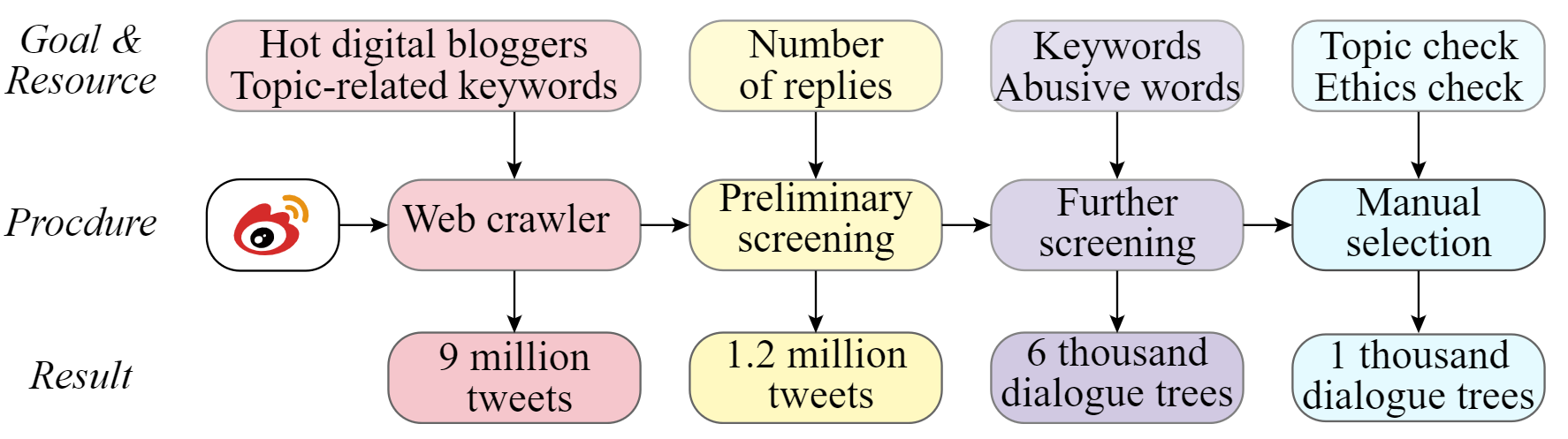
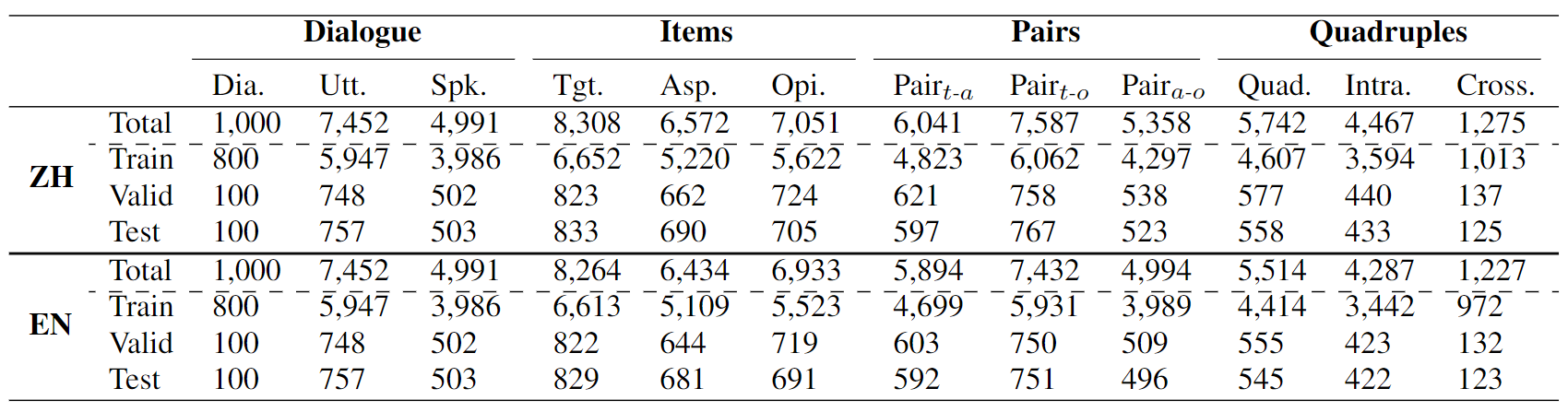
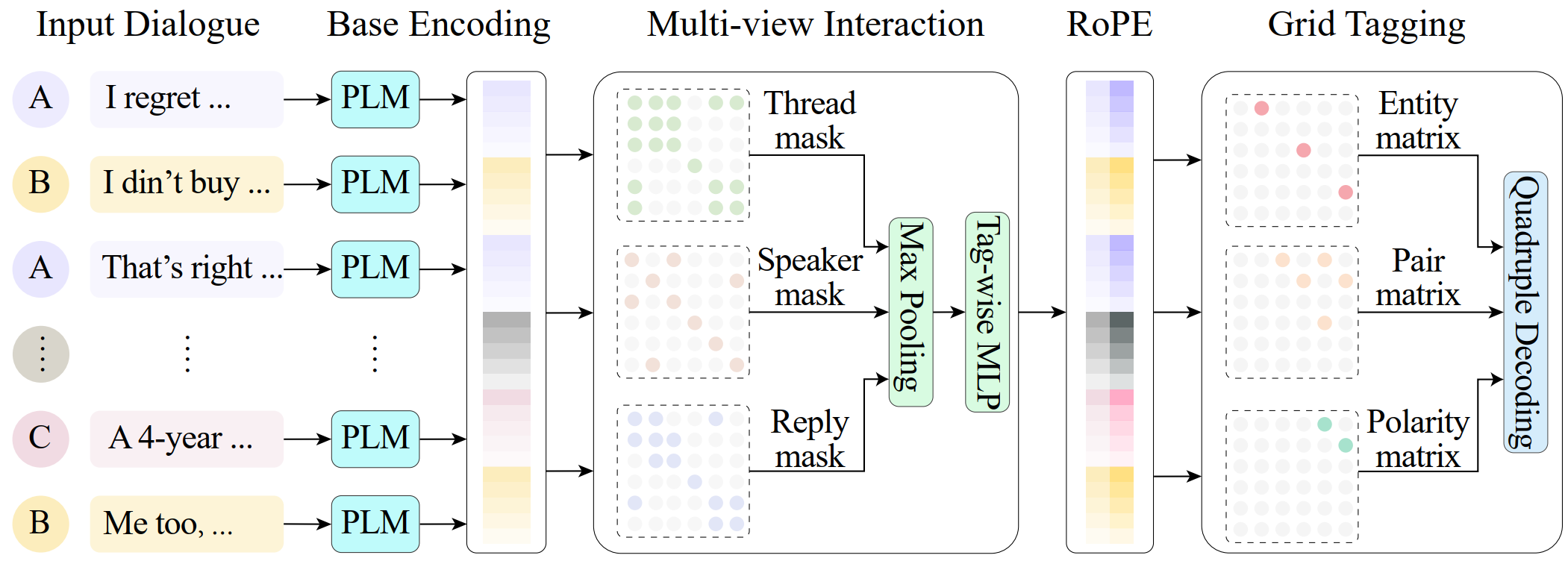
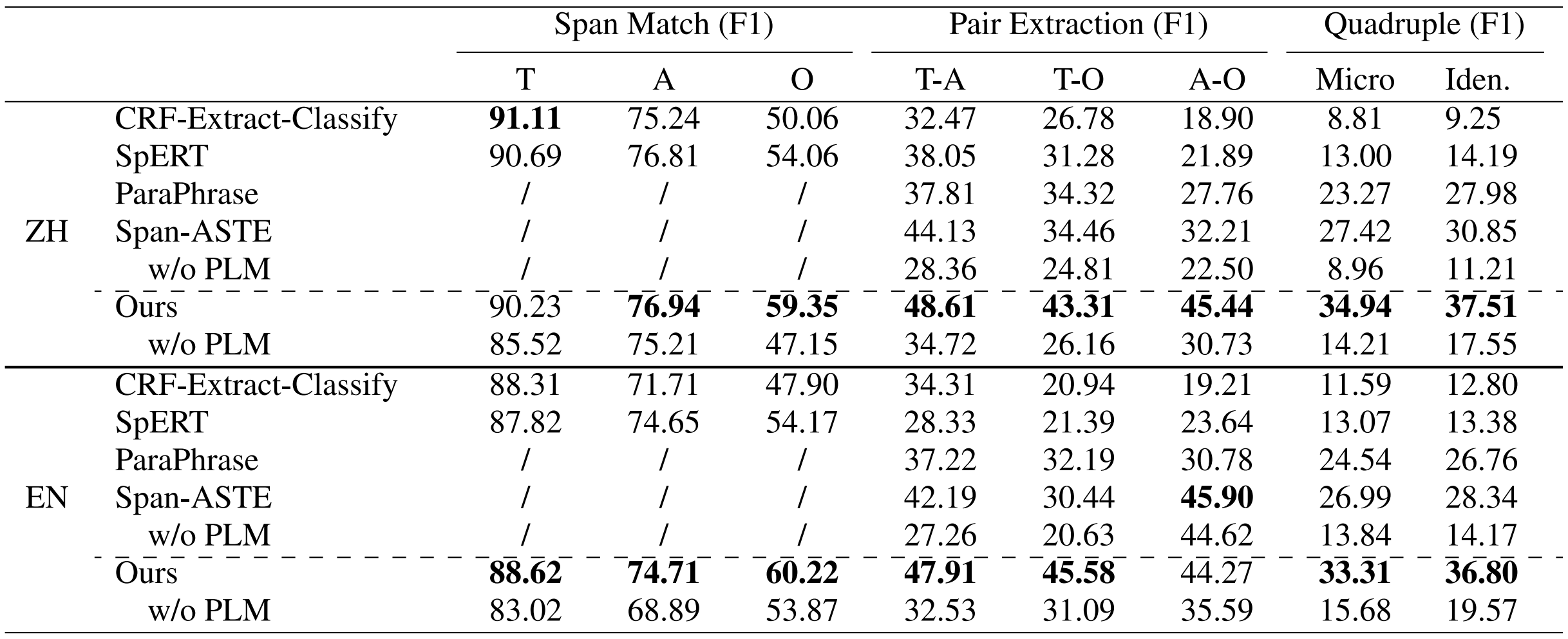
To address this gap, inspired by previous ABSA quadruple research, we propose a new task called Conversational Aspect Sentiment Quadruplet Analysis (DiaASQ).
This task focuses on analyzing multi-party dialogues to identify and extract aspect-level sentiment quadruplets.
These quadruples capture opinions expressed about specific aspects related to a particular target, along with their corresponding sentiment polarity.
For example, in Figure 1, we aim to extract quadruplets such as ('Xiaomi 11', 'WiFi module', 'bad design', 'negative'), ('Xiaomi 11', 'battery life', 'not well', 'negative'), and ('Xiaomi 6', 'screen quality', 'very nice', 'positive') from the dialogues.